엑셀 순위 함수 – 엑셀 RANK 함수는 데이터의 순위 매기기, 데이터의 순위 계산 및 정렬을 실시하는 엑셀 기본 함수입니다. 정확하게 엑셀 숫자의 순위를 매기는 함수이며, 중복 값에 대해서는 동일한 순위를 산출한다는 특징이 있습니다.

엑셀 순위 매기기 기본 정보
Rank 함수를 사용하여 숫자의 순위를 계산하겠습니다.
Rank 함수
순위 함수의 정의와 함수구문에 대해서 알아보겠습니다.
정의
엑셀에서 사용되는 함수 중 하나로, 주어진 데이터 범위 내에서 특정 값의 순위를 계산하는 데 사용됩니다. 이 함수는 데이터를 기준으로 정렬하고, 해당 값이 몇 번째로 크거나 작은지를 판별하여 순위를 반환합니다.
함수구문
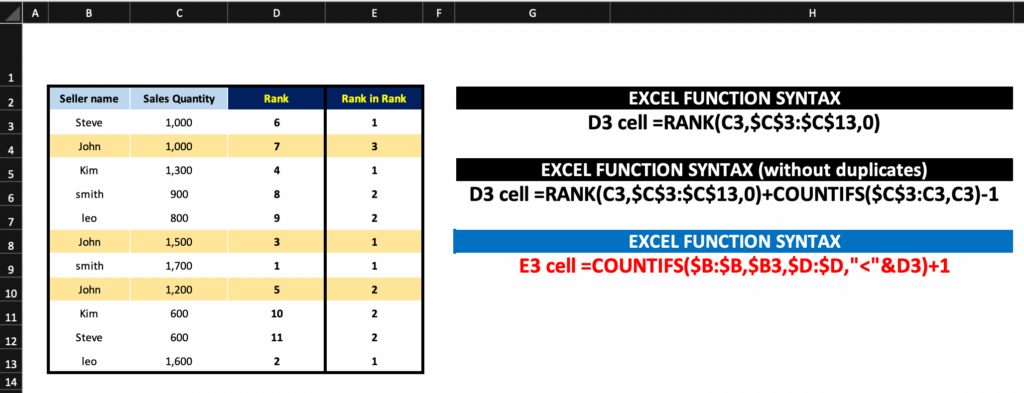
= RANK(값, 범위, [순서])
- 값: 순위를 계산하고자 하는 값을 지정합니다.
- 범위: 순위를 계산할 데이터가 포함된 범위를 지정합니다.
- 순서: 선택적으로 사용되며, 순위를 계산하는 방법을 지정합니다. 오름차순으로 순위를 매기려면 0 또는 생략하고, 내림차순으로 순위를 매기려면 1을 입력합니다.
엑셀 순위 매기기 예제 (중복 순위 포함)
RANK 함수를 활용한 순위 매기기의 기본 예제에 대해서 알아보겠습니다.
아래와 같이 판매자별 판매수량에 순위를 입력하였습니다.
D3 cell =RANK(C3,$C$3:$C$13,0)
함수 구문에서 유의할 점은 절대참조의 사용입니다.
엑셀 순위 매기기 예제 (중복 순위 없이)
순위 매기기 기본 방식으로 실시 할 경우 순위의 중복값을 확인 할 수 있습니다.
엑셀 중복값을 확인 하는 방법 중 가장 효율적인 방법은 아래와 같이 “조건부 서식“을 사용하는 방법입니다.
엑셀에서 순위를 중복값 없이 산출하는 함수 구문은 아래와 같습니다.
D3 cell =RANK(C3,$C$3:$C$13,0)+COUNTIFS($C$3:C3,C3)-1
위의 함수 구문은 COUNTIFS 함수를 사용하여 기준값과 같은 행의 범위까지에서 중복값이 없을 때 까지는 원래의 순위를 산출하고, 중복값이 발견 됬을 때는 1의 숫자를 순위에 더해 순위 값이 중복을 우선 되는 행으로 정리하였습니다.

엑셀 순위 매기기 예제 (순위 안에 순위 매기기)
판매수량으로 산출 한 순위를 각각의 판매자 안의 순위로 변경하는 함수 구문은 아래와 같습니다.
E3 cell =COUNTIFS($B:$B,$B3,$D:$D,”<“&D3)+1
해당 함수는 판매자의 지정 순위 중 가장 작은 순위 1위의 순위로 그 이후의 순위에는 1을 더한 순위를 산출합니다.
결론
엑셀에서 순위를 구하고 해당 순위의 중복값을 제거하는 것은 데이터 분석에서 매우 유용한 기능입니다. 이를 활용하면 다음과 같은 이점을 얻을 수 있습니다.
- 데이터의 상대적인 순위 파악: RANK 함수를 사용하여 데이터의 상대적인 순위를 파악할 수 있습니다. 이를 통해 데이터의 분포나 특징을 파악하고, 비교 및 분석에 활용할 수 있습니다.
- 중복값 제거: 중복값을 제거하면 데이터의 정확성과 일관성을 높일 수 있습니다. RANK 함수를 사용하여 중복값의 순위를 계산하고, 중복된 값을 제거하면 데이터의 중복성을 줄이고 분석 결과의 신뢰성을 높일 수 있습니다.
- 순위 기반 필터링: RANK 함수를 사용하여 데이터를 기준으로 정렬하고, 순위를 계산한 후, 특정 순위 이상 또는 이하의 데이터만 필터링할 수 있습니다. 이를 통해 원하는 범위의 데이터만 추출하여 분석할 수 있으며, 데이터의 양을 줄이고 분석 효율성을 높일 수 있습니다.
- 등수 및 순위별 집계: RANK 함수를 사용하여 데이터를 기준으로 등수 또는 순위를 계산한 후, 해당 등수나 순위에 따라 데이터를 집계할 수 있습니다. 이를 통해 데이터의 특성을 파악하고, 비교 및 분석에 활용할 수 있습니다.
따라서, RANK 함수를 사용하여 순위를 구하고 중복값을 제거하는 것은 데이터 분석에서 매우 유용한 기능이며, 데이터의 정확성과 일관성을 높이고, 분석 효율성을 높일 수 있는 방법입니다.